




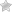 (3,84)
(3,84)Data science spája štatistiku, dátovú analytiku a machine learning pod jeden interdisciplinárny obor. Nebudem sa však zdržiavať porovnávaním jednotlivých definícií a radšej vám na konkrétnom príklade priblížim prirodzený posun za hranice dátovej analytiky a výhody z toho plynúce. Veď aj ľudský mozog dokáže lepšie spracovávať a uchovávať informácie, ktoré sú vo forme príbehu a nie poučiek.
Z doby excelovej do doby data analytickej
Predstavme si fiktívnu firmu, ktorá má sieť maloobchodných predajní. Len pred nedávnom si manažment uvedomil, že rozhodovať sa na základe dát ponúka lepšie výsledky, ako posudzovať situáciu iba pomocou predpokladov, skúsenosti a pocitov. Firma sa prehupla z doby excelovej do doby data analytickej. Implementácia dátovej analytiky do všetkých zákutí, od vrcholového manažmentu až po vedúcich predajní, priniesla nečakané výsledky. Dáta má k dispozícii každý, kto ich potrebuje a v momente kedy ich potrebuje. Nemusia sa už obracať na IT oddelenie a čakať, kým im potrebné dáta vytiahnu z databázy do excelov. Ľudia vo firme už nemusia každý mesiac tráviť dlhé hodiny tvorbou pravidelných reportov, nakoľko tie sa generujú automaticky každý deň. A čo viac – na dáta v reportoch sa dá spoľahnúť, nakoľko sa chyby pri nesprávnom nadefinovaní funkcie VLOOKUP vytratili.
Firma má k dispozícii vždy aktuálne KPI, trendy, medzimesačné zmeny – to všetko rozpadnuté na jednotlivé obchody, produkty a zodpovedných manažérov. Zároveň všetky rozhodnutia manažmentu plynú z dôkladnej dátovej analýzy. Inými slovami, táto firma využila potenciál dátovej analytiky naplno a ocitla sa tak na pomyselnom dátovom Olympe.
Nasledujú ďalšie výzvy
Novonadobudnuté poznanie chcú pretaviť do ďalšej optimalizácie. Z tohto dôvodu potrebujú odhadovať objem predaja jednotlivých dní najbližších pár mesiacov dopredu. Dopyt po ich tovare je do veľkej miery sezónna záležitosť – nárast predaja je značný najmä počas predvianočného obdobia. Firma preto použije objem predaja v predchádzajúcom roku ako východzí bod pre vznikajúcu predikciu.

Predaj firmy – všimnite si významný nárast počas predvianočného obdobia
Sezónnosť je však významná aj v rámci týždňa. Soboty majú pravidelne oveľa nižšie predaje ako piatky. Jedna z možností ako to vyriešiť, je posunúť časový rad o pár dní tak, aby porovnávali predaj v pondelok s pondelom približne pred rokom. Tu sa situácia začína komplikovať, nakoľko takéto posunutie časového radu spôsobí narušenie porovnávania počas sviatkov, ktoré majú spravidla nižšie predaje ako bežné dni.
Ďalšie otázky sa vynárajú pri medziročnom raste. Objem predaja sa každoročne zvyšuje a minuloročné dáta je teda potrebné vynásobiť nejakým koeficientom rastu. Otázne je, aký výpočet zvoliť, nakoľko veľkosť koeficientu bude mať významný vplyv na finálnu predikciu. Vzorec môže byť jednoduchý, objem predaja za určité aktuálne obdobie podelené objemom predaja za relevantné obdobie v minulom roku. Dostaneme však iný výsledok, ak budeme porovnávať medzi sebou roky, posledných 30 dní, alebo predchádzajúci deň. V tomto smere už neexistuje žiadna jednoznačná odpoveď.

Je veľký rozdiel, či predpokladáte medziročné tempo rastu 12% alebo 6%.
Najväčšou komplikáciou sú však externé faktory, ktoré môžu výrazne zmeniť objem predaja. Naša fiktívna firma má približne každý druhý týždeň promo akcie vo všetkých predajniach. Nie je to však pravidlo, nakoľko manažment sa môže rozhodnúť upraviť periodicitu podľa aktuálnych potrieb. V takomto prípade existuje možnosť využiť ďalší koeficient, ktorý bude udávať, o koľko budú predaje vyššie ak v danom týždni bude prebiehať promo akcia. Určiť takýto koeficient je však náročná úloha, nakoľko je potrebné pri jeho výpočte eliminovať vplyvy ostatných faktorov, napr. sezónnosť alebo sviatky.
Naša firma tak padá z dátového Olympu tam kde začínala. Pre vytvorenie predikcie totiž potrebuje vychádzať z predpokladov, určiť koeficienty a priebežne ich upravovať.
Data Science: Z doby data analytickej do doby data vedeckej
Logicky je však vyššie popísané uvažovanie správne, vo firme si uvedomujú, od akých faktorov skutočný predaj a akým spôsobom naň vplývajú. Prechod za hranice jednoduchej dátovej analytiky je potom prirodzený a štatistika nám môže v tomto smere pomôcť. Ak túto logiku zapracujeme do štatistického modelu, vieme sa jednoducho odraziť od údajov predaja v minulých rokoch, vyriešiť sezónnosti, sviatky, trend rastu a aj promo týždne. Týmto faktorom, alebo vysvetľujúcim premenným, ako ich v štatistike voláme, vieme priradiť koeficienty podobne ako v prípade popísanom vyššie. Výsledné koeficienty sú však presnejšie a jednoznačne vychádzajú z údajov, ktoré máme k dispozícii.
Aký by mal byť teda vhodný postup pri tvorbe predikcie? Jednou z možností je tzv. dekompozícia časového radu (v našom prípade objem predaja v jednotlivých dňoch), na trend, ročnú sezónnu zložku, týždenú sezónnu zložku a vplyvy externých faktorov (napr. promo týždeň áno/nie, sviatok áno/nie). Následne na základe jednotlivých zložiek vieme odhadnúť budúci objem predaja v určitý deň. Veľkým bonusom je, že v súčasnosti existujú nástroje, ktoré túto predikciu vedia spraviť vo veľkej miere samostatne. Napríklad voľne dostupný nástroj Prophet, ktorý vytvoril tím ľudí v spoločnosti Facebook poskytuje dobré výsledky predikcií aj bez toho, aby bolo nutné venovať veľa času nastavovaniu parametrov, ktoré do modelu vstupujú.

Princíp dekompozície časového radu
Na následnom obrázku môžeme vidieť porovnanie výslednej predikcie, skutočného predaja a pôvodnú alternatívu („odhad“ zostrojený na základe údajov o predaji v minulom roku, vynásobených koeficientom 1,06 pre zohľadnenie rastu). Už pri letmom pohľade vidíme, že zostrojený odhad na základe minulého roku je často významne nadhodnotený alebo podhodnotený. Je to spôsobené práve promo týždňami (napr. keď minulý rok nebol promo týždeň a tento rok je, odhad je podhodnotený). Predikcia založená na štatistickom prístupe si však aj s týmto faktorom vie pomerne dobre poradiť.

Na krátkom výseku časového radu môžeme vidieť, že predikcia zostrojená nástrojom Prophet kopíruje skutočnosť lepšie ako upravené hodnoty predchádzajúceho roku
Pár slov na záver
Zapojením štatistiky tak vieme určiť odhad predaja na druhý deň, o týždeň, alebo o mesiac oveľa presnejšie, ako keby sme sa snažili vychádzať iba z údajov za minulý rok. Naviac nám takýto prístup pomáha simulovať rôzne situácie pomocou tzv. What-If analýzy a zodpovedať otázky ako napríklad „Aký bude objem predaja o týždeň, ak budeme mať promo týždeň?“, prípadne ak si predstavíme našu firmu ako sieť zmrzlinární: „Aký bude predaj o mesiac ak bude slnečno a 30°C?“. Tým sme však vyčerpali iba malý zlomok otázok, na ktoré štatistika/machine learning/data science vie dať odpoveď.
Našej firme zostáva posledná úloha. Tým, že v rámci data science sa najčastejšie používajú open-source programovacie jazyky R a Python (jeden z nich by sme použili aj pre spomínaný Prophet), ktoré sa postarajú o štatistický model, je vhodné výsledky posunúť do firemného BI, aby mohli užívatelia naprieč celej firmy čerpať z tejto pridanej hodnoty. V ďalšom pokračovaní si povieme, ako môžeme implementovať danú predikciu priamo do BI nástroja Qlik Sense.
—
Budem vďačný za akékoľvek pripomienky, podnety či inšpirácie v komentoch či e-mailom na juracek@emarkanalytics.com. Tiež vás pozývam prečítať si moje ďalšie blogy.




